背景
入行这么多年,一直混迹在网络管理或 最近数年K8S 私有化部署的软件层面。这两年虽然也开始折腾大模型,跟英伟达、沐曦、壁仞、燧原、天数(及其各类马甲)GPU 打交道,但主要集中在k8s 、驱动和模型适配的“软”层面上。
没成想,2025年底的最后一个多月,生活给了我一个大惊喜。我不小心一脚跨进了 GPU 硬件基础设施的深水区。正如标题所言,这是一场关于“AI 基础设施体验”的深度体验。
*(注:为了保住饭碗,具体客户和项目名已隐去,以下内容纯属硬核技术流水账)*
第一幕:销售嘴里“半天”的活儿
故事的开始总是极其草率。
某个周四晚上,大概8点半,回家的地铁上,领导电话来了:“郊区机房有批 GPU 集群,你过去支持下性能测试就行,半天,顶多一天。”
我看着手机屏幕,心想:*真的是去机房跑个脚本的事吗?* 领导也表示怀疑,说去现场看了就知道了。
随后发来一张截图,上面列着几个生僻的测试名称和几个模糊不清的压测指标——这就是我当时的全部情报。当晚,我硬是靠着搜索引擎,把这些工具一个个下载下来,折腾到凌晨12点多,才勉强把测试环境包装进U盘。
第二天,揣着那个存满“弹药”的U盘,我满怀信心地杀向机房所在地。
到了现场,发现我前一晚准备的U盘工具白费了,这里基本都有。跟驻场工程师和项目经理一聊,冷汗就下来了。还卡在dhcp 装机 这个阶段摸索中,甚至连装机后的 ip地址都不敢固定,结果后面一堆冲突,测试基本是在u盘系统下搞的,这哪是性能测试啊,这分明是从零开始搞基建!
那一刻,我深刻领悟了一个真理:销售的嘴,骗人的鬼。
中午我意识到事情的严重,我厚着脸皮电话把领导请过来支援,第一天,我们直接干到凌晨3点。接下来的周末简直就是噩梦:3天睡了16小时,凌晨的机房边上的小黑屋成了第二个家。周日中午,销售和高层终于拉了个会议,把事情的全貌托盘而出——虽然晚了点,但好歹后方支援团队终于进来了。
接下来的十几天,凌晨1-3点下班是常态,甚至后面客户叫停了几天让我们短暂回血后,又是无休止的现场奋战。
第二幕:机房里的“冰火两重天”与听觉轰炸
虽然大部分时间我都在机房外的工作间里敲键盘,但只要进机房排查网口、模块或线路,那就是一场肉体的修行。
你要问我机房的体感?那是冰火两重天:机器前面吹过来的风是刺骨的冷,机器后面排出来的风是滚烫的热。
你要问我机房的听觉?那是一场无休止的工业噪音。
整个机房的噪音从未低于过 80 分贝,一旦走到机器附近,基本都在 90 分贝上下徘徊。最要命的是某款 B 卡机器,开关机的时候简直像起飞一样,直接干到了 100 分贝以上。
*(此处插入手机分贝计截图为证:app提醒我是“割草机”、“地铁列车”的场景)*
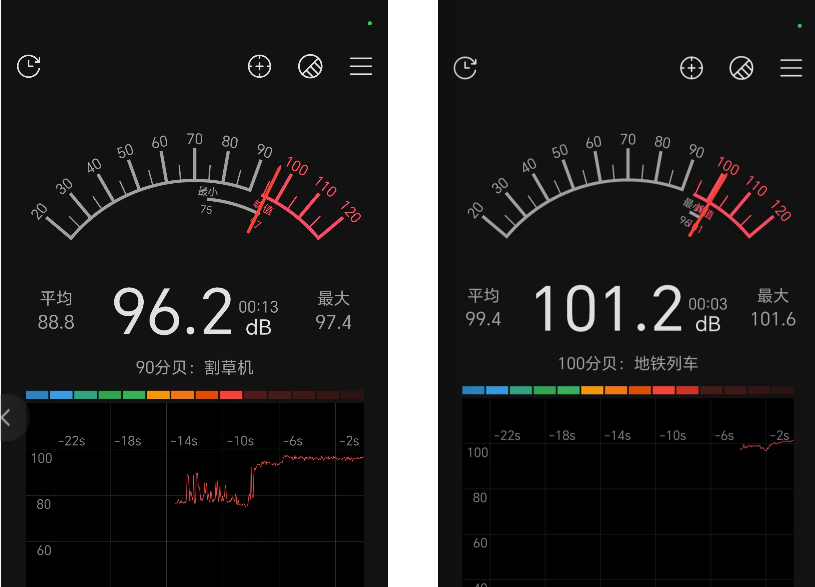
每次进去排查,就像站在地铁隧道里等车。当天回家后我老实了,立马下单了好几副便携式降噪耳塞。后来偶尔进机房,哪怕只待几分钟,我也一定把耳塞塞得紧紧的。
有时候站在那轰鸣的机柜前,我不禁在想:要是这些机器将来交付后满负荷跑起来,这附近的噪音该有多恐怖啊?
第三幕:我在机房干了啥?(AI 也没我想的那么聪明)
这一个多月,我到底在搞什么?看着这张充满错误的 AI 生成示意图(凑合看吧),我把这数百台设备(月底远程支持超数千台)的坑坑洼洼大概梳理了一下。
这张图是ai 画的,有不少错误,仅供参考。

1. 物理装机与“灵魂”初始化
首先是纯体力与脑力的结合。配合完成全部 GPU 服务器的上架、理线、上下电。(其实这部分是服务器厂商和机房运维等工程师干的,这样写,显得自己也吃了体力上的苦)
针对某2款高端卡 H 卡和 B 卡两种机型,因为规格不同,我们对每批机器进行差异化 BIOS 配置、网卡模式切换、启动顺序调整。
后来为了不被累死,眼睛不瞎,我写了几个脚本来采集 BMC 地址和业务网卡 MAC 地址还有其他信息。那一刻,效率提升不说,还没了人工手抄的差错,我觉得我终于开始有些收获了。
2. 网络“迷宫”搭建与玄学排查
接下来是 IB(InfiniBand)网卡和第二业务网的静态 IP 配置。
这块最折腾,特别是那几十台 B 卡机器,IB 卡地址配置后各种报错down。
- 互换排除法:排查掉卡或 IB 卡不通,很多时候是光纤模块或线的问题。这时候就得像换灯泡一样,在机房里把模块或线拔来拔去,通过互换定位故障点。
- 重启大法失灵:软件层面上故障,我们没招后一般会重启解决,ib 卡这边不吃这一套,越重启,掉的卡越多。然后又陷入回机房检查模块和线路的循环。
- 冷重启的魔力:最近发现了几台奇怪的机器,某几个IB 卡down或者 GPU 掉卡,厂商报修换了模块都不行。结果同事试着冷重启主机(完全断电再上电),居然就好了!看来与我们常说的重启大法不一样,硬件有时候也需要“断电重启”这一招大杀法。
最后配合客户做完 GPU 节点的 IB 网络连通性测试和误码率测试或多机测试,针对发现的网段不通问题及时反馈并协助排查。
3. 压测支持与掉卡“惊魂”
早期全程跟进 GPU 集群压测、装机,从单节点到多机分布式。
过程中不仅调脚本,还得处理各种奇葩问题:SSH 连不上、IB 网卡模式抽风、GPU 驱动兼容性冲突。
最惊心动魄的是,临近第一波交付前一个周末,上午过来发现数百台节点有“掉卡” 而且ib卡名也全变了,发现压测的工程师半夜干了一个我至今没搞清具体啥破坏的事,反正我排查的现象是某个服务停了。这可是大事,我立即摇人,排查修复,下午确保集群相关服务正常,ib 卡全部测通,不然验收这关过不了。
4. 自动化“外挂”
为了省事,我定制了几个小镜像,借用 BMC 挂载 ISO 的能力,一口气配置好 2 块业务网卡(后期的存储服务器甚至得配 4 块)。ps. 这2波机器没走pxe 装机,直接用了厂商的u盘装机,没有配置网络。
这一趟下来,大概写了 10 多个大小脚本。坦白说,其中一半的功劳得算在 AI 头上——毕竟我也是边问 AI 边写代码,主打一个“人机合一”。
第四幕:两种“心酸”的碰撞
回想起这两年的技术经历,真是两种不同的折磨:
以前适配国产 GPU 时,心酸在于“脑子累”。
那时候面对的是一个个莫名其妙的驱动报错、框架不兼容。你在屏幕前死磕代码,联系厂商工程师要文档,那种无力感是逻辑层面的。你是在跟软件的缺陷博弈。
现在搞英伟达硬件基建,心酸在于“身子累”。
现在是物理层面的攻击。你要忍受 100 分贝的噪音,忍受忽冷忽热的风,还要在几千根线缆里排查那个松动的模块。虽然英伟达的生态相对成熟,驱动问题少些,但当硬件规模上来后,物理连接、散热、电源、信号干扰……任何一个物理环节出问题,都会让你在机房里走到腿断。
以前是“为什么代码跑不通”的焦虑,现在是“为什么这块灯不亮”的崩溃,更崩溃的是,模块所有灯都正常,为何不通。可以说,一个折磨灵魂,一个折磨肉体。
第五幕:当前卡住的 BOSS(Supermicro SUM vs MFT)
虽然流程基本跑通了,但还留着一个让我头秃的遗留问题,特此记录,恳请各路大神指点:
【场景描述】
H 服务器插了 10 张 CX-7 网卡:
- Slot 9 和 11:作为业务网卡;
- 其他 8 张:给 GPU 用的 IB 卡。
网卡部分架构如下图
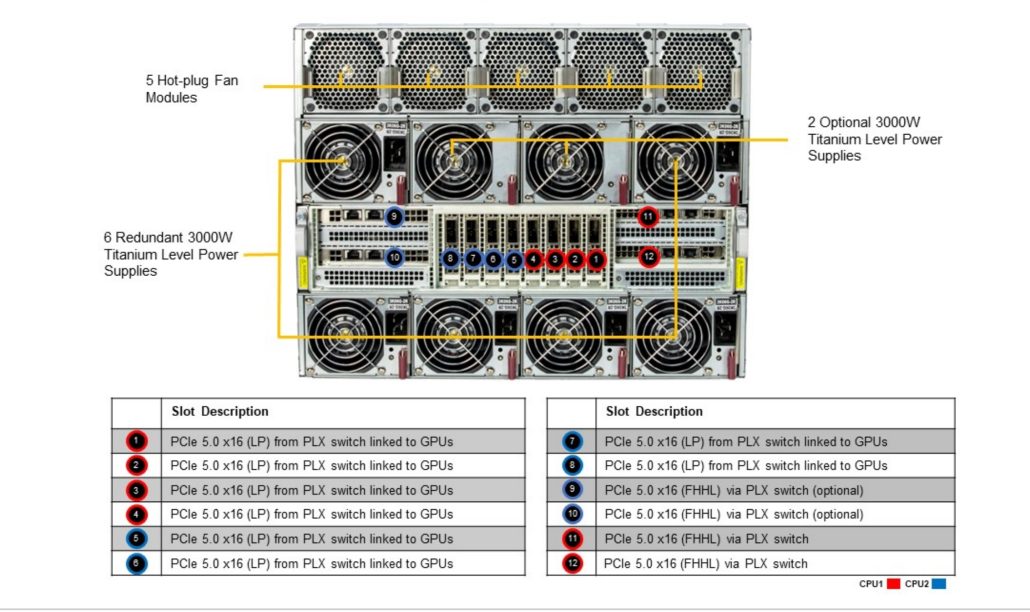
【核心痛点】
PXE 装机前,必须先把业务网卡模式和EFI Retry以及业务网卡启动顺序改对,否则装机会卡住,目前是纯人工手动设置的。
【目前的坑】
我研究数天 Supermicro Update Manager (SUM),发现这玩意儿在 UEFI BIOS 下搞不定这个事。问了几个 AI,它们众口一词:“你自己定制个包含 mft(主要是 mlxconfig)的工具,再加一系列脚本和镜像来实现。”
我这几天在就在这一步死磕摸索中。如果有大佬路过,欢迎不吝赐教!
总结
回想这一个多月,从最初某人口中的“半天兼职”,到现在硬刚 几千台设备的 AI 基础设施建设。
虽然过程极其熬人,被噪音轰炸,被冷热交替折腾,看着凌晨三四点的机房天花板和机房外的小黑屋怀疑人生,回家后,发现附近的早餐点都开始营业了,你是啥感受,但看着集群绿灯常亮、压测通过的那一刻,那种成就感也是实打实的。
2025 的结尾,虽然没有诗和远方,但有 GPU、有脚本、有降噪耳塞(顺带最近2周还给老婆和自己各整了一幅降噪耳机),还有一群一起熬夜的兄弟,挺好。

文章评论