<span class="line"><span class="comment">#!/usr/bin/env python</span></span>
<span class="line"><span class="comment">#-*- coding:utf-8 -*-</span></span>
<span class="line">import os</span>
<span class="line">import <span class="built_in">time</span></span>
<span class="line">def run():</span>
<span class="line"> <span class="built_in">result</span> = []</span>
<span class="line"> timestamp = <span class="built_in">time</span>.strftime(<span class="string">'%Y-%m-%d %H:%M:%S'</span>, <span class="built_in">time</span>.localtime(<span class="built_in">time</span>.<span class="built_in">time</span>()))</span>
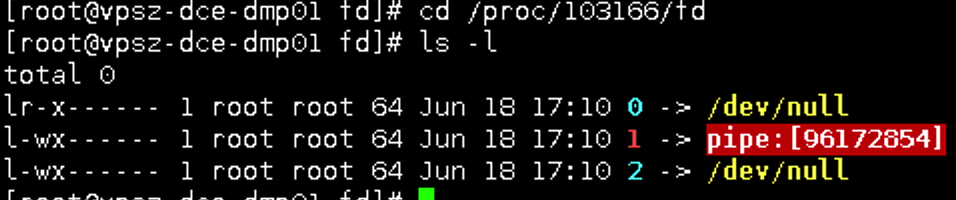
<span class="line"> cmd = <span class="string">'ps auxf'</span></span>
<span class="line"> ret = os.popen(cmd).readlines()</span>
<span class="line"> <span class="keyword">for</span> i <span class="keyword">in</span> ret:</span>
<span class="line"> <span class="keyword">item</span> = i.<span class="built_in">split</span>()</span>
<span class="line"> <span class="keyword">if</span> <span class="built_in">len</span>(<span class="keyword">item</span>) > <span class="number">7</span>:</span>
<span class="line"> <span class="keyword">item</span> = <span class="keyword">item</span>[<span class="number">7</span>]</span>
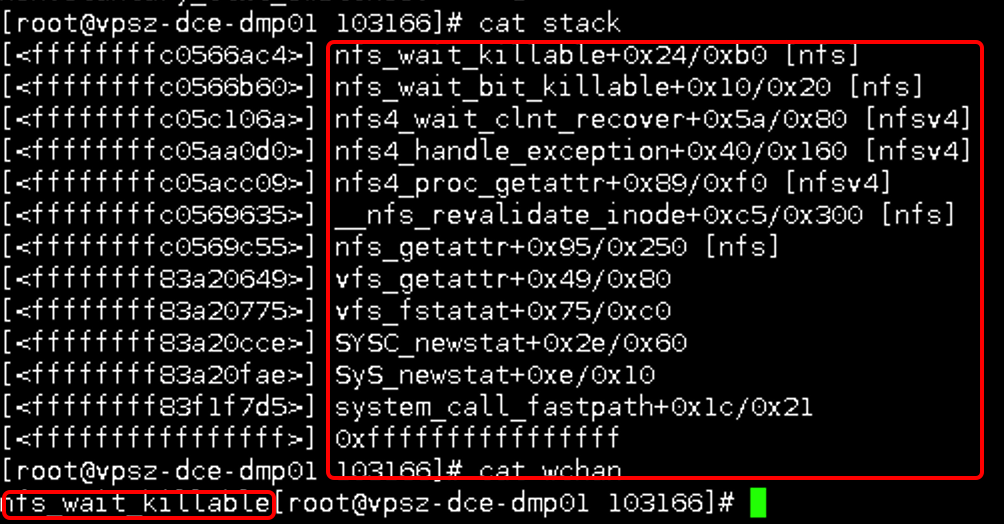
<span class="line"> <span class="keyword">if</span> <span class="keyword">item</span> == <span class="string">'D'</span>:</span>
<span class="line"> <span class="built_in">result</span>.append(i)</span>
<span class="line"> <span class="keyword">for</span> r <span class="keyword">in</span> <span class="built_in">result</span>:</span>
<span class="line"> <span class="built_in">process</span> = <span class="string">'%s %s'</span> % ( timestamp,r[:<span class="number">-1</span>])</span>
<span class="line"> print <span class="built_in">process</span></span>
<span class="line"> <span class="keyword">if</span> <span class="built_in">result</span>:</span>
<span class="line"> print <span class="string">'\n'</span></span>
<span class="line"><span class="keyword">if</span> __name__ == <span class="string">"__main__"</span>:</span>
<span class="line"> <span class="keyword">while</span> True:</span>
<span class="line"> run()</span>
<span class="line"> <span class="built_in">time</span>.sleep(<span class="number">0.5</span>)</span>
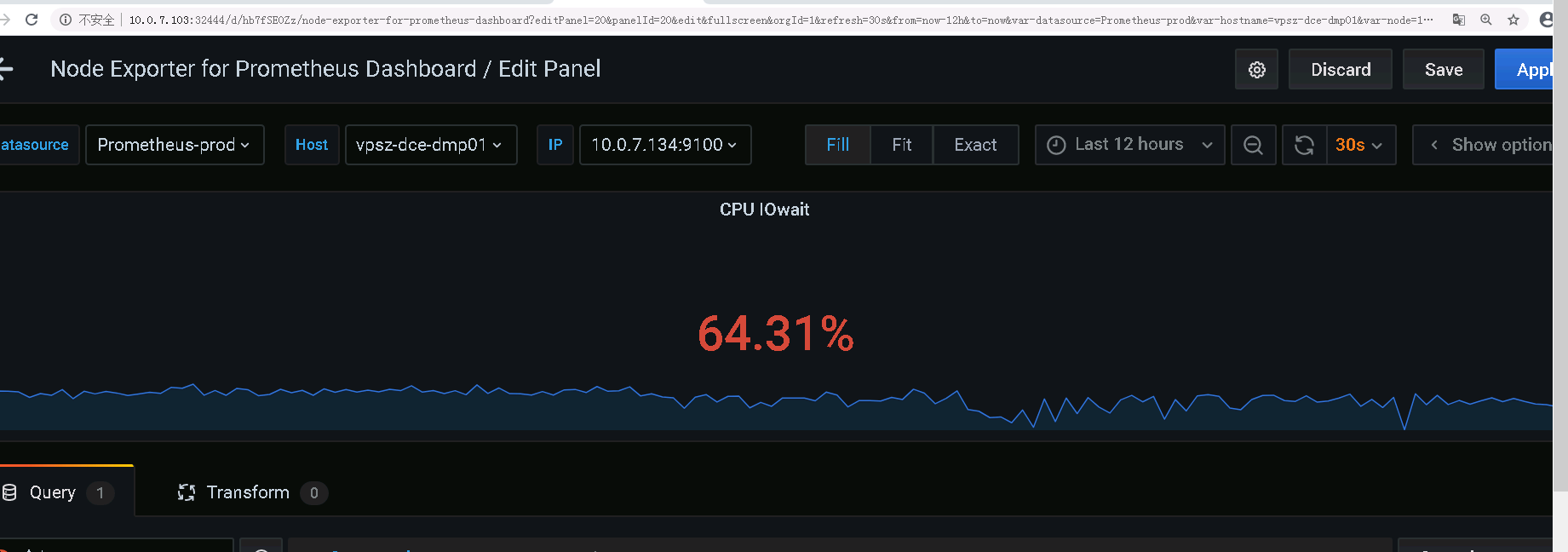
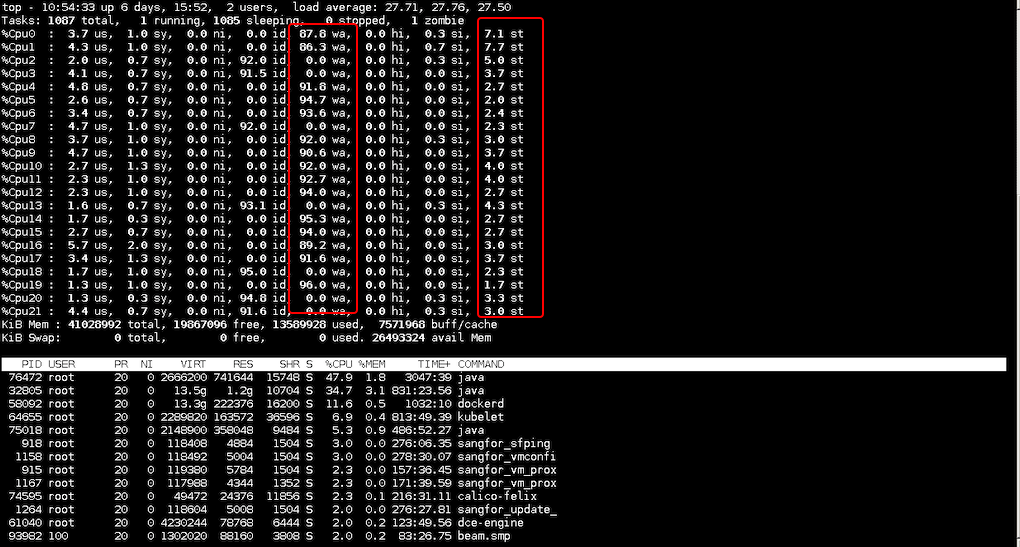
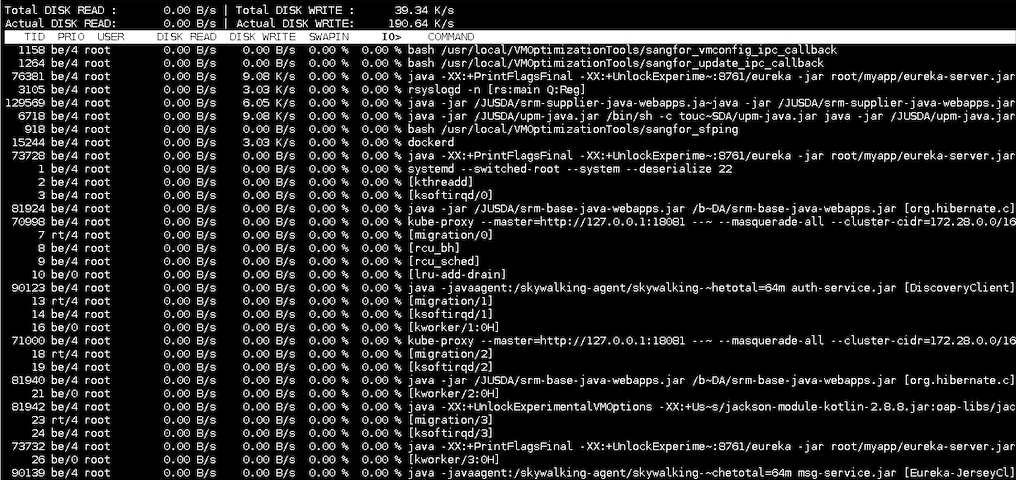


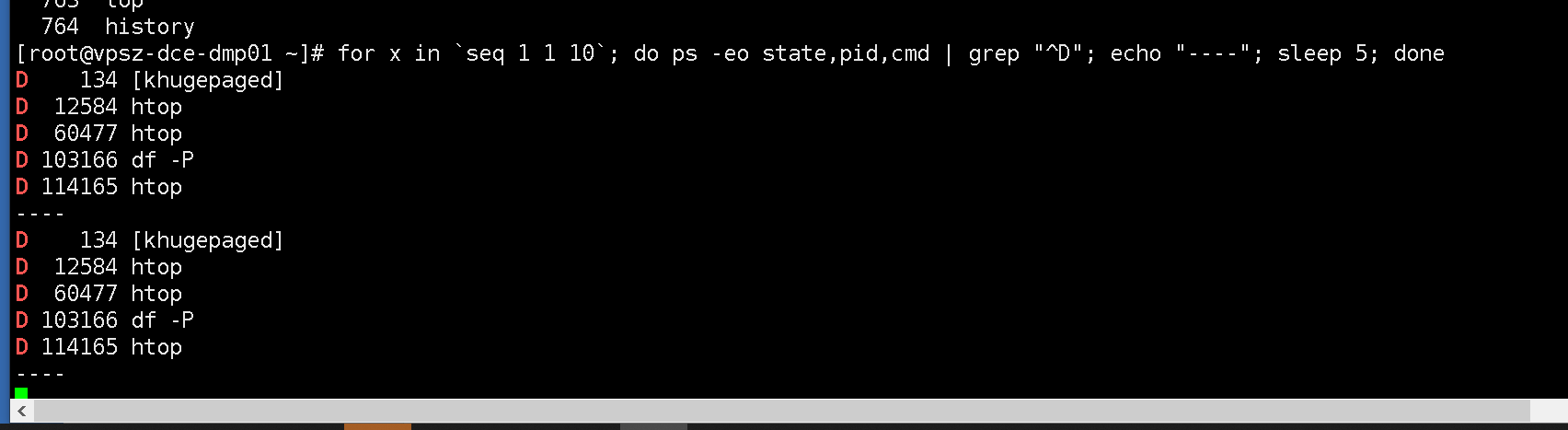


文章评论