背景:
过去2-3年,不时会搞虚拟机容器的 GPU。最早从小组的老旧卡 TITAN Xp 开始,后面接触了内外部环境的一些卡,比如 3080、4090、L40S、Tesla P4、P80、K100、A6000,甚至还碰到了一张禁售的卡,顺便说一句,装这张卡的驱动真是费劲,由于电源和nvlink的关系,还出现了掉卡的情况,最终请了大佬出马才搞定。
开始的时候,虚拟机用的是 ESXi 7.0 版本,但是 GPU 的支持有问题。有一台机器是独立使用的,还有一张卡是通过虚拟化 GPU 软件 Bitfusion 分给多个虚拟机用的。得安装对应系统的 Bitfusion 客户端,然后再把虚拟机设置成 Bitfusion 客户端。后来突然就直接用直通模式了,不再用 Bitfusion 软件。
搞完 Docker 或 Containerd 还有卡的驱动,搭了个最简单的 Kubernetes 集群,给同事们用来训练大型模型。然后到了23年初,GPT 热起来了,在物理机上折腾 GPU 卡的次数也多了一些。上周又碰到了一个新的驱动问题,赶紧整理了下我过去的注意事项和踩过的坑。
虚拟机部分
开机前准备
普通虚拟机模版即可,克隆需要的虚拟机。
查看所在物理机gpu卡的绑定信息
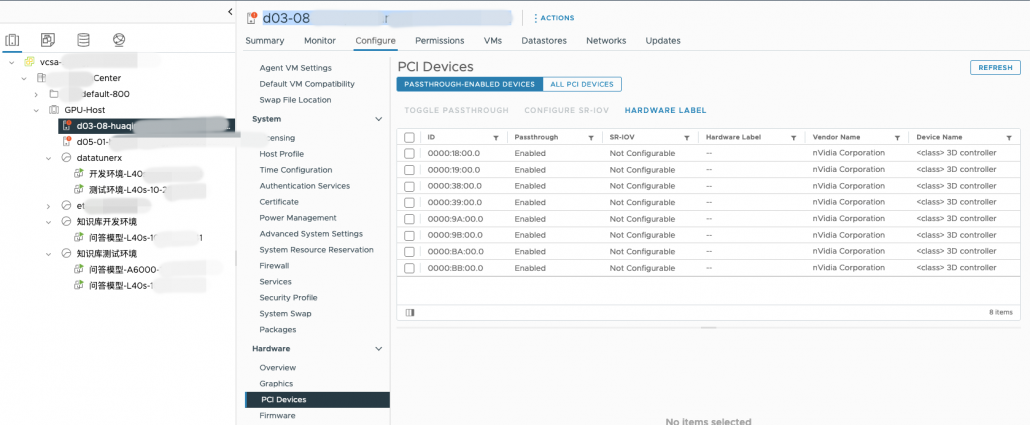
如果 gpu 卡已经被其他虚拟机使用,类似下图,可以看到卡被某个虚拟机占用了。
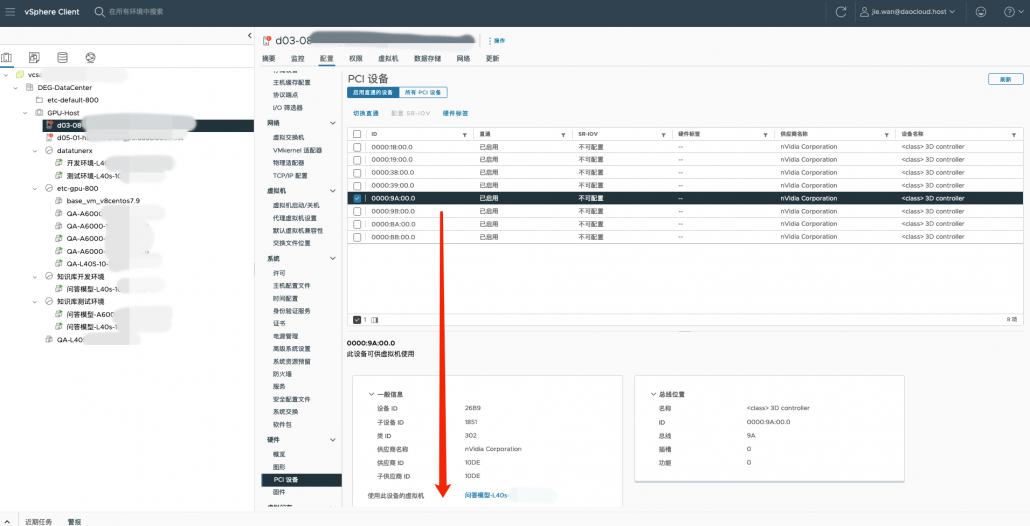
如果某个卡没被占有,那么就可以给新的虚拟机使用了。
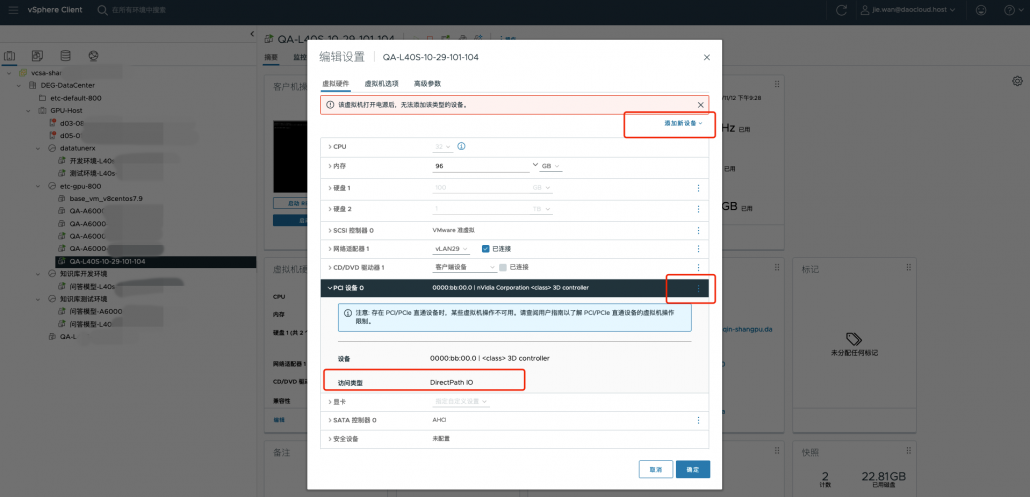
给需要的虚拟机增加PCI设备,选择gpu卡,添加pci 设备,选择前面的未使用bb:00卡,并选择 DirectPath IO 直通模式
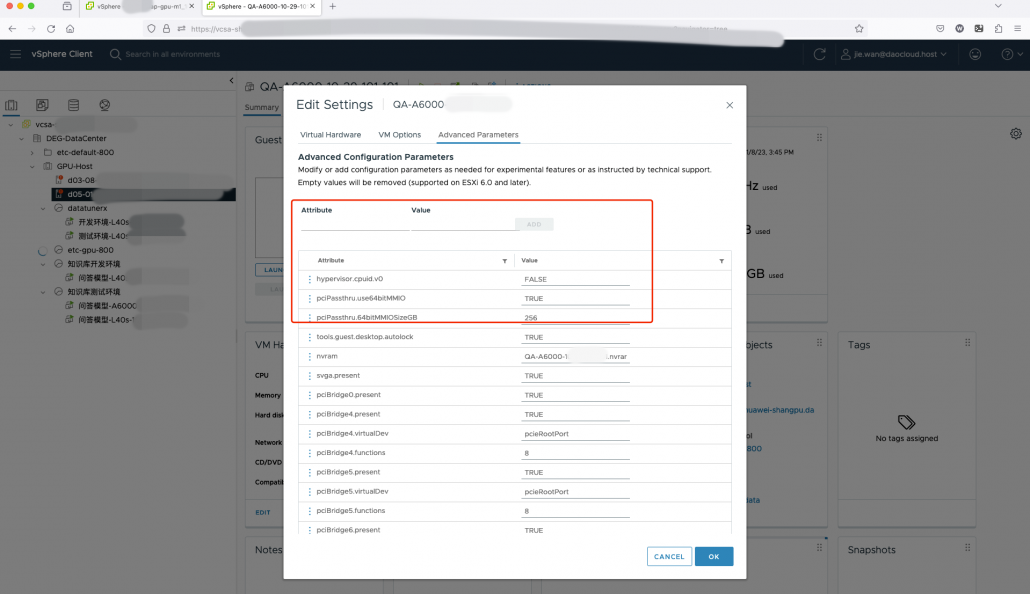
在“虚拟机选项” →"高级" ->"配置参数"→ "编辑配置" 里面,添加如下参数
禁用命令
|
|
echo "blacklist nouveau" > /etc/modprobe.d/denylist.conf echo "options nouveau modeset=0" >> /etc/modprobe.d/denylist.conf ps,根据虚拟机操作系统不同,有些微的差别,可参考 https://docs.nvidia.com/ai-enterprise/deployment-guide-vmware/0.1.0/nouveau.html dracut --force reboot |
重启后,再查看 lsmod | grep nouveau ,无任何输出了,禁用生效
有小伙伴问,为啥要禁用 官网readme,里面一段引用一下,大概是说非 nvidia 默认驱动有冲突,需要禁用。
|
|
What is Nouveau, and why do I need to disable it? Nouveau is a display driver for NVIDIA GPUs, developed as an open-source project through reverse-engineering of the NVIDIA driver. It ships with many current Linux distributions as the default display driver for NVIDIA hardware. It is not developed or supported by NVIDIA, and is not related to the NVIDIA driver, other than the fact that both Nouveau and the NVIDIA driver are capable of driving NVIDIA GPUs. Only one driver can control a GPU at a time, so if a GPU is being driven by the Nouveau driver, Nouveau must be disabled before installing the NVIDIA driver. Nouveau performs modesets in the kernel. This can make disabling Nouveau difficult, as the kernel modeset is used to display a framebuffer console, which means that Nouveau will be in use even if X is not running. As long as Nouveau is in use, its kernel module cannot be unloaded, which will prevent the NVIDIA kernel module from loading. It is therefore important to make sure that Nouveau's kernel modesetting is disabled before installing the NVIDIA driver. |
重点来了
安装依赖,非常容易踩坑,貌似我这个步骤还不够精简。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
yum -y install epel-release yum -y install gcc gcc-c++ dkms yum install kernel-devel-$(uname -r) kernel-headers-$(uname -r) yum install libXext pkgconfig wget -c https://rpmfind.net/linux/centos/7.9.2009/os/x86_64/Packages/libvdpau-1.1.1-3.el7.x86_64.rpm rpm -ivh libvdpau-1.1.1-3.el7.x86_64.rpm wget https://qiniu-download-public.daocloud.io/opensource/tmp-vulkan-filesystem-1.1.97.0-1.el7.noarch.rpm- -O vulkan-filesystem-1.1.97.0-1.el7.noarch.rpm rpm -ivh vulkan-filesystem-1.1.97.0-1.el7.noarch.rpm curl -s -L https://nvidia.github.io/libnvidia-container/stable/rpm/nvidia-container-toolkit.repo | sudo tee /etc/yum.repos.d/nvidia-container-toolkit.repo yum -y install nvidia-driver-latest-dkms cuda cuda-drivers -y wget https://developer.download.nvidia.com/compute/cuda/11.8.0/local_installers/cuda-repo-rhel7-11-8-local-11.8.0_520.61.05-1.x86_64.rpm rpm -ivh cuda-repo-rhel7-11-8-local-11.8.0_520.61.05-1.x86_64.rpm # 上面2行是当时的离线版方式 ,这里cuda的版本要和 run那个驱动有一点对应关系 ## 下面4行是 官方 在线版方式 sudo yum-config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/rhel7/x86_64/cuda-rhel7.repo sudo yum clean all sudo yum -y install nvidia-driver-latest-dkms cuda sudo yum -y install cuda-drivers # 忘了这个应该在什么时候执行了 wget -O /etc/yum.repos.d/epel.repo https://mirrors.aliyun.com/repo/epel-7.repo yum-config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/rhel7/x86_64/cuda-rhel7.repo # 安装前面下载的具体卡驱动 chmod +x NVIDIA-Linux-x86_64-535.104.05.run ./NVIDIA-Linux-x86_64-535.104.05.run |
正常情况下 执行 安装会很顺利,类似如下图


偶尔也有意外,上周就遇到了一个坑,现象就是提示这个驱动安装失败,查看日志有类似如下报错。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
./include/asm-generic/bug.h:62:57: note: in expansion of macro 'BUG' #define BUG_ON(condition) do { if (unlikely(condition)) BUG(); } while (0) ^ /tmp/selfgz89934/NVIDIA-Linux-x86_64-535.154.05/kernel/common/inc/nv-linux.h:1041:5: note: in expansion of macro 'BUG_ON' BUG_ON(nv_bar_index >= NV_GPU_NUM_BARS); ^ In file included from /tmp/selfgz89934/NVIDIA-Linux-x86_64-535.154.05/kernel/nvidia/linux_nvswitch.h:28:0, from /tmp/selfgz89934/NVIDIA-Linux-x86_64-535.154.05/kernel/nvidia/i2c_nvswitch.c:24: /tmp/selfgz89934/NVIDIA-Linux-x86_64-535.154.05/kernel/common/inc/nv-linux.h: In function 'offline_numa_memory_callback': /tmp/selfgz89934/NVIDIA-Linux-x86_64-535.154.05/kernel/common/inc/nv-linux.h:2000:5: error: implicit declaration of function 'offline_and_remove_memory' [-Werror=implicit-function-declaration] pNumaInfo->ret = offline_and_remove_memory(pNumaInfo->base, ^ cc1: some warnings being treated as errors make[3]: *** [/tmp/selfgz89934/NVIDIA-Linux-x86_64-535.154.05/kernel/nvidia/i2c_nvswitch.o] Error 1 make[3]: Target `__build' not remade because of errors. make[2]: *** [/tmp/selfgz89934/NVIDIA-Linux-x86_64-535.154.05/kernel] Error 2 make[2]: Target `modules' not remade because of errors. make[1]: *** [sub-make] Error 2 make[1]: Target `modules' not remade because of errors. make[1]: Leaving directory `/usr/src/kernels/5.4.267-1.el7.elrepo.x86_64' make: *** [modules] Error 2 ERROR: The nvidia kernel module was not created. ERROR: Installation has failed. Please see the file '/var/log/nvidia-installer.log' for details. You may find suggestions on fixing installation problems in the README available on the Linux driver download page at www.nvidia.com. 。。。。。 ./include/linux/acpi.h:65:6: note: in expansion of macro 'WARN_ON' if (WARN_ON(!is_acpi_static_node(fwnode))) ^ In file included from <command-line>:0:0: ././include/linux/compiler_types.h:214:24: warning: ISO C90 forbids mixed declarations and code [-Wdeclaration-after-statement] #define asm_inline asm __inline ^ ./arch/x86/include/asm/bug.h:35:2: note: in expansion of macro 'asm_inline' asm_inline volatile("1:\t" ins "\n" \ ^ ./arch/x86/include/asm/bug.h:79:2: note: in expansion of macro '_BUG_FLAGS' _BUG_FLAGS(ASM_UD2, BUGFLAG_WARNING|(flags)); \ ^ ./include/asm-generic/bug.h:90:19: note: in expansion of macro '__WARN_FLAGS' #define __WARN() __WARN_FLAGS(BUGFLAG_TAINT(TAINT_WARN)) ^ ./include/asm-generic/bug.h:115:3: note: in expansion of macro '__WARN' __WARN(); \ |
一番搜索,证实了自己的怀疑,编译器和内核适配的锅。
系统没变,一直是centos7.9或ubuntu 22.04,内核 3.10.1160 系列,这次是内核 5.4.267-1 ,差别上来了。
解决办法就是更新系统gcc ,从默认的 4.8.5 ,升级到9.3.1
|
|
sudo yum install -y http://mirror.centos.org/centos/7/extras/x86_64/Packages/centos-release-scl-rh-2-3.el7.centos.noarch.rpm sudo yum install -y http://mirror.centos.org/centos/7/extras/x86_64/Packages/centos-release-scl-2-3.el7.centos.noarch.rpm sudo yum install devtoolset-9-gcc-c++ 永久生效 source /opt/rh/devtoolset-9/enable 或者临时会话生效 scl enable devtoolset-9 bash 再次查看 g++ --version |
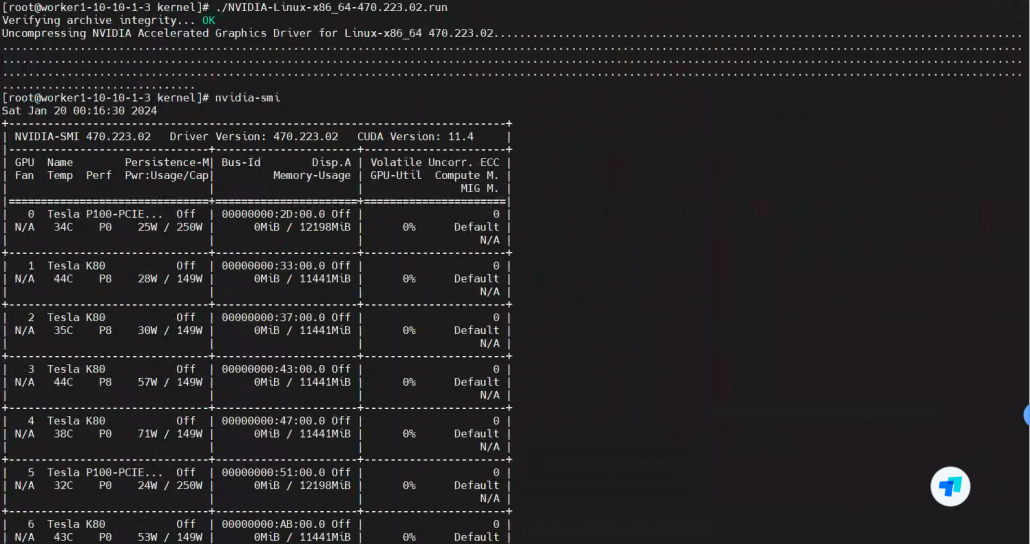
能正常识别后,驱动算是告一段落。
接着安装 k8s 集群,略。
然后替代默认的 运行时
|
|
curl -s -L https://nvidia.github.io/libnvidia-container/stable/rpm/nvidia-container-toolkit.repo | \ sudo tee /etc/yum.repos.d/nvidia-container-toolkit.repo sudo yum install -y nvidia-container-toolkit nvidia-container-toolkit-base 运行 nvidia-ctk runtime configure --runtime=containerd 自动修改 /etc/containerd/config.toml systemctl restart containerd |
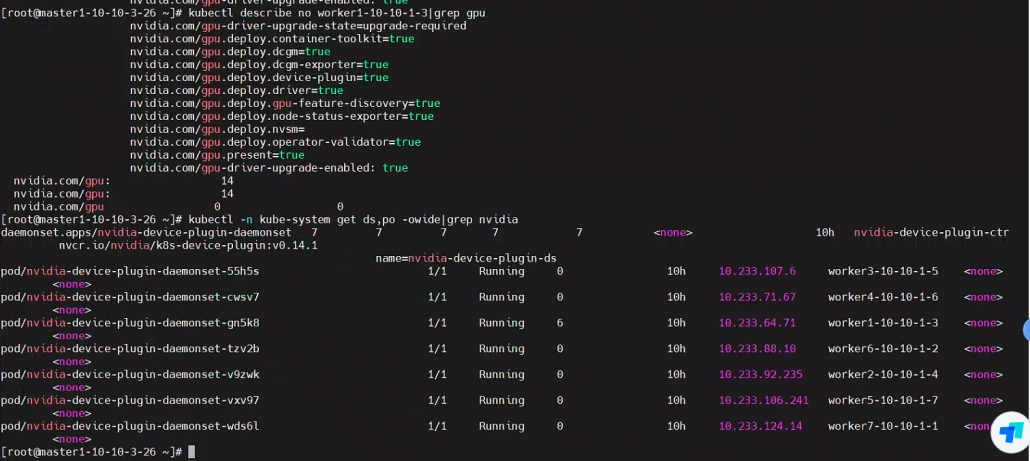
集群启用gpu 支持,安装一个 nvidia-device-plugin 的 daemonset
kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.14.1/nvidia-device-plugin.yml
部署通过

测试 cuda 应用
|
|
cat cude.pod.yaml apiVersion: v1 kind: Pod metadata: name: gpu-pod spec: restartPolicy: Never containers: - name: cuda-container image: nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda10.2 resources: limits: nvidia.com/gpu: 1 |
kubectl apply -f cude.pod.yaml
可以发现这个应用很快运行完成
gpu-pod 0/1 Completed 0 6s
查看日志也正常了
|
|
kubectl logs gpu-pod [Vector addition of 50000 elements] Copy input data from the host memory to the CUDA device CUDA kernel launch with 196 blocks of 256 threads Copy output data from the CUDA device to the host memory Test PASSED Done |
前面运行时替代的坑
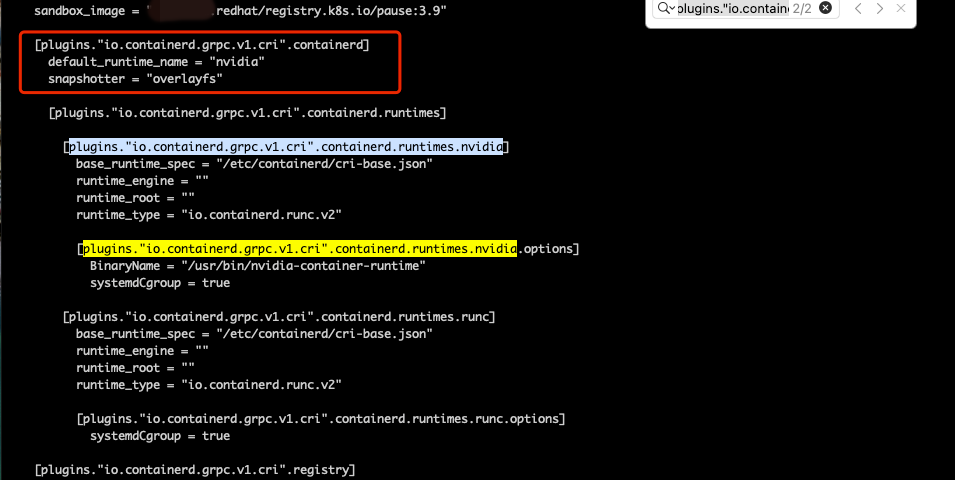
修改gpu节点运行时,以前是手动修改 /etc/containerd/config.toml 文件
这次 nvidia-ctk runtime configure --runtime=containerd 命令配置,扫了一眼,看起来配置都加上了
结果部署gpu应用识别失败,一直pending
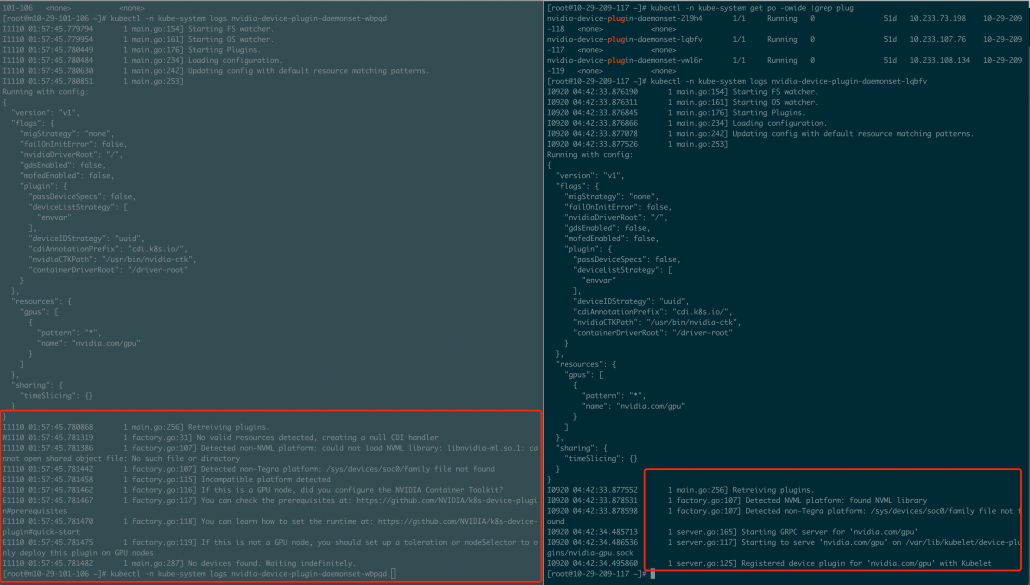
查看 ds pod,运行正常 ,细看日志,有报错
Detected non-NVML platform: could not load NVML: libnvidia-ml.so.1: cannot open shared object file: No such file or directory
再次查看 /etc/containerd/config.toml 文件,发现 default_runtime_name = "runc",修改为 nvidia 后重启 containerd 即可。



文章评论