背景
最近接触到了不少GPU机器,有H100、 H800、H20、 A800、 rtx 4090 ,还有国产的 沐曦 MetaX C500、壁仞Biren110E、燧原S60。 今天简单测试一下沐曦 MetaX C500上面部署 DeepSeek-R1-Llama-70B 模型
官方文档 Metax C500-DeepSeek R1蒸馏模型推 理部署手册是基于docker 部署的,这里改成k8s 的sts方式部署,然后做了几个简单测试,效果看起来不错。
准备工作
本次实际为 8卡 物理机,理论部署 70b 4张卡足够了。沐曦官方介绍如下:
在推理中,我们可以根据下面的公式 估算得到推理所需要的显存大小。
|
1 2 |
1. FP16/BF16(半精度): = 参数 x2 x 1.2 2. INT8 (整数): = 参数 x 1.1 |
从上面的公式中可以得出,使用70B的模型大多数默认使用的是BF16进行推理,进行推理大 概需要 70 x 2 x 1.2=168GB, 此外还需要考虑kv cache的显存占用, 其计算公式可参考如 下
|
1 2 |
num_hidden_layers * head_dim * seq_len * bs * 2 * precission # 这里若采用 bfloat16精度则占用两个字节,即需要乘以2 |
另外, vllm会根据预设的显存池大小来计算预留的block, 越长的context通常需要越多 block。综合以上考虑, 70B模型的C500推理推荐四卡以上。
https://sw-download.metax-tech.com/index 这里下载 容器镜像
下载 DeepSeek-R1-Distill-Llama-70B 模型文件 (modelscope、或 huggingface) 大概 132G ,本次存放位置为 gpu 节点 /root/vllm/DeepSeek-R1-Distill-Llama-70B
正式开始
部署脚本
含sts和svc
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 |
kind: StatefulSet apiVersion: apps/v1 metadata: name: deepseek-r1-sts namespace: deepseek spec: replicas: 2 selector: matchLabels: app: deepseek-r1-sts template: metadata: creationTimestamp: null labels: app: deepseek-r1-sts spec: volumes: - name: dshm emptyDir: medium: Memory sizeLimit: 10Gi - name: data hostPath: path: /root/vllm/DeepSeek-R1-Distill-Llama-70B type: DirectoryOrCreate - name: tokenizer hostPath: path: /root/vllm/DeepSeek-R1-Distill-Llama-70B type: DirectoryOrCreate containers: - name: container-1 image: inference-llm-deepseekr1_opt:v2 command: - /bin/bash - '-c' args: - | export PATH="/opt/conda/bin:$PATH" if [ "$POD_INDEX" = "0" ]; then ray start --head --port=5000 --num-gpus=4 vllm serve /root/vllm/DeepSeek-R1-Distill-Llama-70B --served-model-name deepseek-r1-70b --trust-remote-code --tensor-parallel-size=4 --pipeline-parallel-size=1 --max-model-len=65536 --enable-reasoning --reasoning-parser deepseek_r1 --enable-chunked-prefill # --enforce-eager else ray start --block --address=deepseek-r1-sts-master:5000 --num-gpus=4 fi env: - name: NCCL_CUMEM_ENABLE value: '0' - name: NCCL_DEBUG value: INFO - name: VLLM_LOGGING_LEVEL value: DEBUG - name: NCCL_IB_DISABLE value: '1' - name: POD_INDEX valueFrom: fieldRef: apiVersion: v1 fieldPath: metadata.labels['apps.kubernetes.io/pod-index'] resources: limits: metax-tech.com/gpu: '4' volumeMounts: - name: dshm mountPath: /dev/shm - name: data mountPath: /root/vllm/DeepSeek-R1-Distill-Llama-70B terminationMessagePath: /dev/termination-log terminationMessagePolicy: File imagePullPolicy: IfNotPresent securityContext: privileged: false restartPolicy: Always terminationGracePeriodSeconds: 30 dnsPolicy: ClusterFirst securityContext: {} affinity: {} schedulerName: default-scheduler tolerations: - key: node.kubernetes.io/not-ready operator: Exists effect: NoExecute tolerationSeconds: 300 - key: node.kubernetes.io/unreachable operator: Exists effect: NoExecute tolerationSeconds: 300 dnsConfig: {} serviceName: '' podManagementPolicy: OrderedReady updateStrategy: type: RollingUpdate rollingUpdate: partition: 0 revisionHistoryLimit: 10 persistentVolumeClaimRetentionPolicy: whenDeleted: Retain whenScaled: Retain --- kind: Service apiVersion: v1 metadata: name: deepseek-r1-sts-master namespace: deepseek spec: ports: - name: tcp-5000 protocol: TCP port: 5000 targetPort: 5000 - name: tcp-8000 protocol: TCP port: 8000 targetPort: 8000 selector: app: deepseek-r1-sts apps.kubernetes.io/pod-index: '0' clusterIP: None clusterIPs: - None type: ClusterIP sessionAffinity: None ipFamilies: - IPv4 ipFamilyPolicy: SingleStack internalTrafficPolicy: Cluster --- kind: Service apiVersion: v1 metadata: name: deepseek-r1-sts-master-external namespace: deepseek spec: ports: - name: tcp-5000 protocol: TCP port: 5000 targetPort: 5000 nodePort: - name: tcp-8000 protocol: TCP port: 8000 targetPort: 8000 nodePort: selector: app: deepseek-r1-sts apps.kubernetes.io/pod-index: '0' clusterIP: clusterIPs: type: NodePort sessionAffinity: None externalTrafficPolicy: Cluster ipFamilies: - IPv4 ipFamilyPolicy: SingleStack internalTrafficPolicy: Cluster |
简单测试
直接curl
|
1 |
curl http://192.168.16.93:31458/v1/completions -H "Content-Type: application/json" -d '{ "model": "deepseek-r1-70b", "prompt": "你是谁,简单用中英日各100字介绍一下你自己", "max_tokens": 2048, "temperature": 0.7}' |
返回如图,效果还行。

简单压测方式1
使用内置脚本,容器内执行,64个并发
|
1 2 3 4 5 |
python /workspace/deepseek/test/benchmark_serving.py \ --model deepseek-r1-70b \ --tokenizer /root/vllm/DeepSeek-R1-Distill-Llama-70B \ --dataset_name random --random_input_len 3072 --random_output_len 1024 --num-prompts 64 \ --trust-remote-code --ignore-eos --port 8000 |
输出结果如下
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
Starting initial single prompt test run... Initial test run completed. Starting main benchmark run... Traffic request rate: inf Burstiness factor: 1.0 (Poisson process) Maximum request concurrency: None 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 64/64 [01:57<00:00, 1.84s/it] ============ Serving Benchmark Result ============ Successful requests: 64 Benchmark duration (s): 117.79 Total input tokens: 196608 Total generated tokens: 65536 Request throughput (req/s): 0.54 Output token throughput (tok/s): 556.37 Total Token throughput (tok/s): 2225.50 ---------------Time to First Token---------------- Mean TTFT (ms): 25564.03 Median TTFT (ms): 25332.88 P99 TTFT (ms): 49867.34 -----Time per Output Token (excl. 1st token)------ Mean TPOT (ms): 87.69 Median TPOT (ms): 88.07 P99 TPOT (ms): 108.19 ---------------Inter-token Latency---------------- Mean ITL (ms): 87.69 Median ITL (ms): 66.53 P99 ITL (ms): 525.14 ================================================== |
测试时mx-smi 的输出
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
Every 2.0s: mx-smi deepseek-r1-sts-1: Sun Mar 16 10:14:45 2025 mx-smi version: 2.1.9 =================== MetaX System Management Interface Log =================== Timestamp : Sun Mar 16 10:14:45 2025 Attached GPUs : 4 +---------------------------------------------------------------------------------+ | MX-SMI 2.1.9 Kernel Mode Driver Version: 2.9.8 | | MACA Version: 2.29.0.18 BIOS Version: 1.20.3.0 | |------------------------------------+---------------------+----------------------+ | GPU NAME | Bus-id | GPU-Util | | Temp Power | Memory-Usage | | |====================================+=====================+======================| | 0 MXC500 | 0000:08:00.0 | 21% | | 44C 125W | 59723/65536 MiB | | +------------------------------------+---------------------+----------------------+ | 1 MXC500 | 0000:09:00.0 | 21% | | 43C 125W | 59243/65536 MiB | | +------------------------------------+---------------------+----------------------+ | 2 MXC500 | 0000:0e:00.0 | 21% | | 43C 129W | 59243/65536 MiB | | +------------------------------------+---------------------+----------------------+ | 3 MXC500 | 0000:11:00.0 | 21% | | 44C 130W | 59243/65536 MiB | | +------------------------------------+---------------------+----------------------+ +---------------------------------------------------------------------------------+ | Process: | | GPU PID Process Name GPU Memory | | Usage(MiB) | |=================================================================================| | 0 326 ray::RayWorkerW 58804 | | 1 327 ray::RayWorkerW 58324 | | 2 328 ray::RayWorkerW 58324 | | 3 329 ray::RayWorkerW 58324 | +---------------------------------------------------------------------------------+ |
压测2
容器外测试工具,100个并发
|
1 |
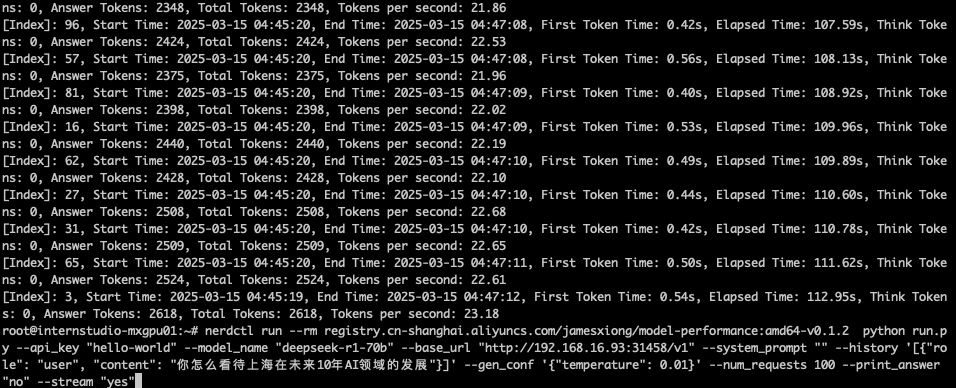
nerdctl run --rm registry.cn-shanghai.aliyuncs.com/jamesxiong/model-performance:amd64-v0.1.2 python run.py --api_key "hello-world" --model_name "deepseek-r1-70b" --base_url "http://192.168.16.93:31458/v1" --system_prompt "" --history '[{"roroot@internstudio-mxgpu01:~# nerdctl run --rm registry.cn-shanghai.aliyuncs.com/jamesxiong/model-performance:amd64-v0.1.2 python run.py --api_key "hello-world" --model_name "deepseek-r1-70b" --base_url "http://192.168.16.93:31458/v1" --system_prompt "" --history '[{"role": "user", "content": "你怎么看待上海在未来10年AI领域的发展"}]' --gen_conf '{"temperature": 0.01}' --num_requests 100 --print_answer "no" --stream "yes" |
平均22 tokens /s 出头的样子,能接受
后记
本次实际用了8张卡,直接改成4张会报oom,需要调整一些参数(例如:降低长度 --max-model-len=4096、 --dtype bfloat16 ),压测效果差了一些,倒是也还能用。
|
1 |
vllm serve /root/vllm/DeepSeek-R1-Distill-Llama-70B --served-model-name deepseek-r1-70b --trust-remote-code --tensor-parallel-size=2 --pipeline-parallel-size=2 --max-model-len=4096 --enable-reasoning --reasoning-parser deepseek_r1 --enable-chunked-prefill --dtype bfloat16# --device cuda #--enforce-eager |
--num-gpus=2 和 metax-tech.com/gpu: '2' 这2个地方(由4改成2)
压测效果如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
Starting initial single prompt test run... Initial test run completed. Starting main benchmark run... Traffic request rate: inf Burstiness factor: 1.0 (Poisson process) Maximum request concurrency: None 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 64/64 [04:17<00:00, 4.02s/it] ============ Serving Benchmark Result ============ Successful requests: 64 Benchmark duration (s): 257.21 Total input tokens: 196608 Total generated tokens: 65536 Request throughput (req/s): 0.25 Output token throughput (tok/s): 254.80 Total Token throughput (tok/s): 1019.19 ---------------Time to First Token---------------- Mean TTFT (ms): 24195.59 Median TTFT (ms): 24104.36 P99 TTFT (ms): 46168.25 -----Time per Output Token (excl. 1st token)------ Mean TPOT (ms): 223.88 Median TPOT (ms): 224.07 P99 TPOT (ms): 241.00 ---------------Inter-token Latency---------------- Mean ITL (ms): 223.88 Median ITL (ms): 205.77 P99 ITL (ms): 962.69 ================================================== |

文章评论