前一阵基于公司产品平台写了一篇容器平台磁盘管理一些思考,用4个词来总结就是:规划->监控->清理→扩容。
导出pdf很长,感觉良好,这里去掉公司产品信息,放一些通用缩水版在这里记录一下。
产品自带监控要优先考虑。
2.1. 邮箱设置
实现监控的第一步,设置邮件服务器(详情略)。
2.2. 监控告警部分
监控仪表盘及告警中心,磁盘是否有告警(详情略)。
如 告警看到disk-m1 磁盘设备 /dev/mapper/centos-root 使用率超过70%
点击右上角告警,看到disk-m1触发了1条磁盘空间告警通知。主机 disk-m1触发时间是 2020年6月11日 11:39分。
查看邮箱, 确实有这封告警信,提示我尽快处理。
Prometheus、 grafana 、node_exporter 等第三方工具磁盘监控,这里也不展开了,有兴趣的搜索关键字 “Prometheus AlertManager 邮件告警“ 有很多文章。
清理是本文的重点,CI/CD 打包过程会有很多镜像,这里主要谈3块,1,镜像仓库相关,2,Prometheus相关,3,ElasticSearch 相关。
流水线每次执行都会留下本地镜像,可以使用脚本定时清理方案。
(同事写的脚本略,可以搜索容器GC、镜像GC等文章或脚本,清理镜像关联的处于退出状态、created的容器、dangling=true状态的镜像等等)
3.2. 镜像仓库清理
CI/CD 过程中会持续往镜像仓库推送镜像,占用大量的容量,若需要对镜像仓库进行清理,可以使用 docker registry API 的方案实现的脚本去库删除镜像仓库中指定的镜像。(同事写的脚本略)
网上有一些脚本实现,不过这里有一个官方api默认值的坑, 删了好几次才发现这个问题,查了资料,官方api默认最大返回值为100. const maximumReturnedEntries = 100 ,这样会导致库比较大的时候,超过100的部分从未被检查过,也就不会被删除。切记注意修改。这里有提到范例 https://docs.docker.com/registry/spec/api/ GET /v2/_catalog?n=整数值 ,这个数字不能少
|
1 |
运行这个命令,清理缓存释放空间。 |
docker exec -it docker-registry /bin/registry garbage-collect /etc/docker/registry/conf.yml
可以用于清理磁盘,删除关闭的容器、无用的数据卷和网络,以及dangling镜像(即无tag的镜像)
这里注意 1 点,要根据业务增长情况来设置日志过期日期。
如果监控发现 prometheus 磁盘增长很快,一天几十数百G的那种,需要修改配置文件,缩减数据保留时间,将原有的15天,缩减为10天或7天,即编排配置文件,容器重启后开始逐步清理,并最终完成。
- 编排文件修改
kubectl edit deploy prometheus-1 -n prod-prometheus
RETENTION value 15d 改成可接受的天数。
如果用到 Skywalking组件往 ES 中写入数据, 目前除了 Skywalking 可以在服务端配置数据清理策略,其他的组件的数据需要通过如下的 cronjob 进行定时清理任务来清理历史数据。
3.6.1. Skywalking 数据清理
Skywalking 主要采集了服务的日志、性能指标等数据。
参考官方skywalking ttlg设置,类似如下 :
|
1 2 3 4 |
<span class="pl-ent"> recordDataTTL</span>: <span class="pl-s">${SW_CORE_RECORD_DATA_TTL:3} </span><span class="pl-c"># Unit is day</span> <span class="pl-ent">metricsDataTTL</span>: <span class="pl-s">${SW_CORE_RECORD_DATA_TTL:7} </span><span class="pl-c"># Unit is day </span> |
3.6.2. ElasticSearch数据清理
|
1 |
<span class="pl-c">建议参考 </span><a href="https://www.elastic.co/guide/en/elasticsearch/reference/current/getting-started-index-lifecycle-management.html">Index Lifecycle 索引生命周期</a> 进行es数据自动清理。 |
理论上,做好磁盘规划、监控、清理的前 3 步,是不需要磁盘扩容的。
4.2. 实际
这里以一个测试环境的案例来简单介绍一下吧,用户突然发现磁盘空间满,查看docker info信息,data space 显示可用 0 字节。
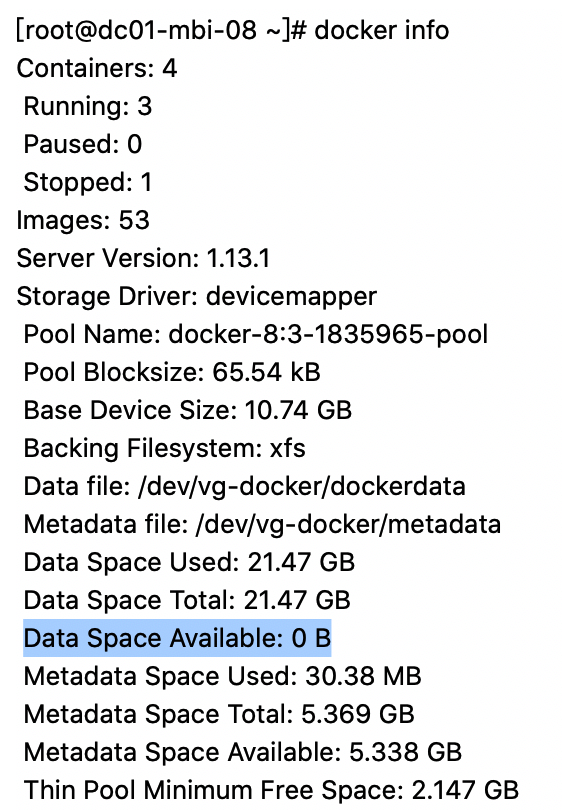
根据 docker info详细信息,得到 Data file的具体目录 /dev/vg-docker/dockerdata 和 vg 名称 vg-docker 。
4.2.1. 方法
提供4步解决方法给用户
- 初始化一个新分区 pvcreate /dev/sde
- 扩容vg ,# vgextend vg-docker /dev/sde
- 扩容data ,# lvextend -l +100%free /dev/vg-docker/dockerdata
- 重启生效 systemctl restart docker
4.2.2. 过程动作及日志
[root@dc01-mbi-08 vg-docker]# pvcreate /dev/sde Physical volume "/dev/sde" successfully created. |
[root@dc01-mbi-08 vg-docker]# vgextend vg-docker /dev/sde Volume group "vg-docker" successfully extended |
[root@dc01-mbi-08 vg-docker]# lvextend -l +100%free /dev/vg-docker/dockerdataSize of logical volume vg-docker/dockerdata changed from 20.00 GiB (5120 extents) to <70.00 GiB (17919 extents).Logical volume vg-docker/dockerdata successfully resized. |
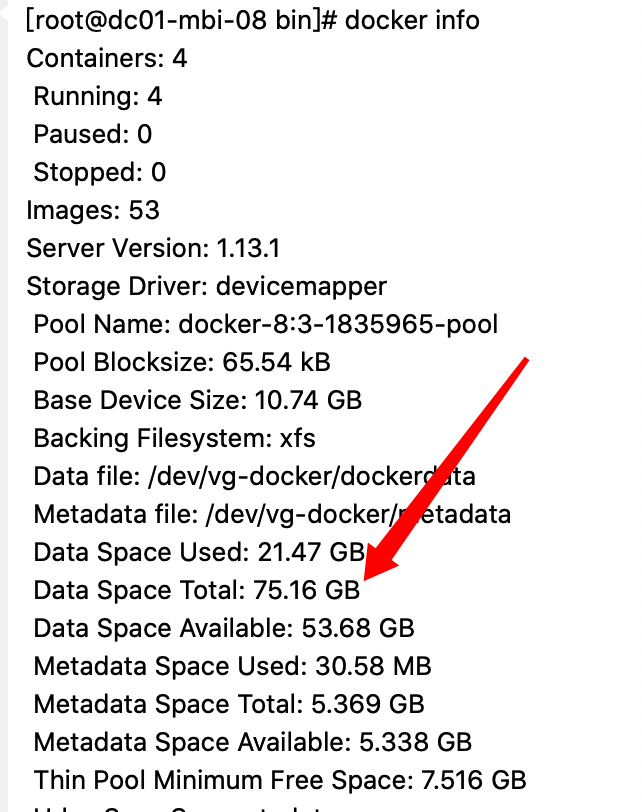
重启 docker ,新增 空间生效,总量75G, 可用53G,扩容完成。

文章评论